
解放大型語言模型的商業應用 - 概念
目前大型語言模型的發展,已經從一開始 ChatGPT 讓人驚豔的生成式回答,開放了各種一般應用的無限可能,但是在導入大型語言模型至企業中實際產品的開發過程,還有很多需要考慮的問題,這篇文章會從概念上介紹幾個方式,讓大家可以更了解如何將大型語言模型導入企業的解決方案。
PS. The concept of this article is based on Andy, Zong-Lin Li comment.
Prompt Engineering
直接呼叫大型語言模型,並透過 Prompt Engineering 的方式,將模型的輸入與輸出,透過良好設計的 Prompt Engineering 技巧,讓目標使用者能夠在企業設定的情境下,透過大型語言模型得到答案。
通常在這個階段,會有一個專門的團隊,負責設計 Prompt Engineering 的技巧,並且透過大量的測試,確保模型的輸入與輸出,能夠符合企業的需求。
完美的氛圍會是,該企業/團隊會有自己維護的 Prompt Template/Prompt Tree,透過 Logging 得到使用者回饋,並持續性的修正 Prompt Template/Prompt Tree。
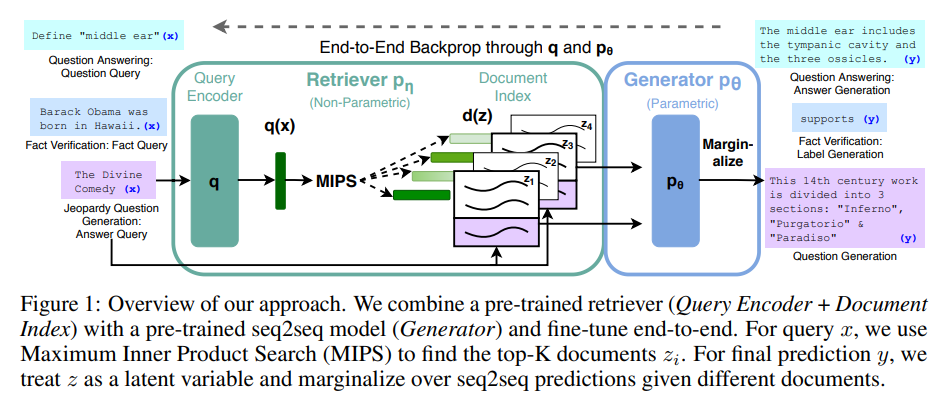
RAG (Retrival Augmented Generation)
透過 RAG (Retrival Augmented Generation) 的方式,將大型語言模型與檢索模型結合,透過外部搜尋結果,找到最相關的結果,並透過大型語言模型,生成最符合使用者需求的答案。
RAG是一種生成自然語言文本的架構,裡面包含Retriever & Generator,流程如下 :
- Retriever 對大規模的資料或企業知識庫進行搜索,找對最相關的文件甚至是段落
- Generator則參考上述所找到的資料產生新的文本
以目前的技術來說
- Retriever 可以是 Azure Cognitive Search, Bing Search etc.
- Generator 可以是 Azure OpenAI model (可以是GPT 3, 3.5, 4)
以目前商業應用與開發速度來說,RAG 的方式,是最符合企業需求的方式,因為企業可以透過打造企業的知識管理/搜尋引擎,找到最符合的資料,並透過大型語言模型,生成最符合使用者需求的答案。
Fine Tuning
在企業商用情境下,透過 Prompt Engineering 將原本的情境,轉換成大量的 Prompt,雖會與原有的應用高度無縫接軌,但是代價會是每次消耗大量的 Token 以及 Latency。
所謂的Fine Tuning指的是讓類神經網路基於預訓練過(pre-trained)的權重之上再做微調,主要目的是讓模型能在特定的場景或任務表現得更好。核心概念就是基於預訓練的模型(GPT 3, 3.5, etc.)再加上自己的數據、調整參數。
所以Fine Tuning並不是re-train生成式AI模型,它只是去影響模型的權重
主要好處如下 :
- Higher quality results than prompt design
- Comparable performance to prompt design by using a large number of examples
- Token savings due to shorter prompts
- Lower latency requests
很多企業會從以前機器學習專案的經驗,想要一開始就從 Fine Tuning 達到自己的客製化需求,但是在目前的大型語言模型的發展階段,Fine Tuning 的方式,還是有很多需要考慮的問題,例如:如何取得訓練資料?如何訓練?如何評估?如何持續性的更新?如何與 Prompt Engineering 結合?等等。
之後幾個部分會針對這三種方式,透過實際的架構,開發方式與工具介紹,讓大家更了解如何透過大型語言模型,解決企業的問題。